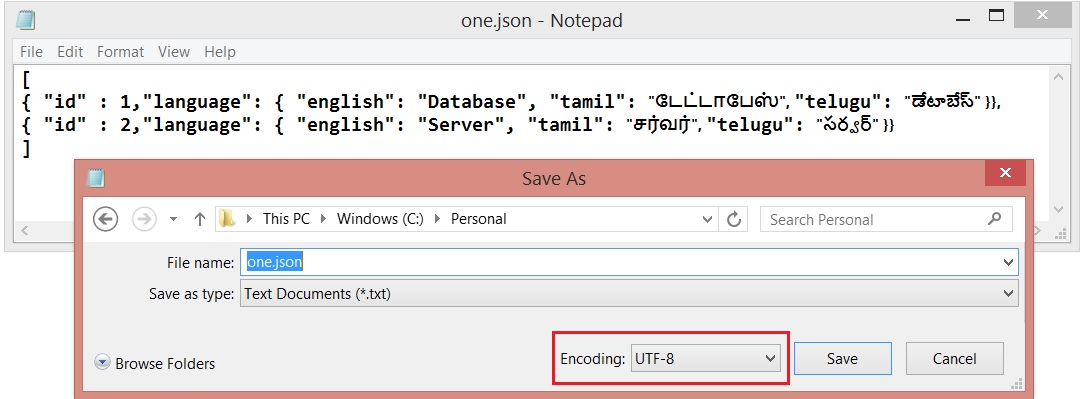
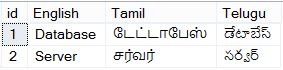
In SQL Server Enterprise edition, There is a strategy being followed when performing SCAN on tables!
Its also called as "Advanced Scanning"
The advanced scan feature allows multiple tasks to share full table scans. If the execution plan of a Transact-SQL statement requires a scan of the data pages in a table and the Database Engine detects that the table is already being scanned for another execution plan, the Database Engine joins the second scan to the first, at the current location of the second scan.
The Database Engine reads each page one time and passes the rows from each page to both execution plans.
This continues until the end of the table's data is reached.
At that point, the first execution plan has the complete results of a scan, but the second execution plan must still retrieve the data pages that were read before it joined the in-progress scan. The scan for the second execution plan then wraps back to the first data page of the table and scans forward to where it joined the first scan. Any number of scans can be combined like this. The Database Engine will keep looping through the data pages until it has completed all the scans. This mechanism is also called "merry-go-round scanning" and demonstrates why the order of the results returned from a SELECT statement cannot be guaranteed without an ORDER BY clause.
i.e:, assume that you have a table with 500000 pages. User-1 executes a Transact-SQL statement that requires a scan of the table. When that scan has processed 100000 pages, User-2 executes another Transact-SQL statement that scans the same table. The Database Engine schedules one set of read requests for pages after 100001, and passes the rows from each page back to both scans. When the scan reaches the 200000 th page, User-3 executes another Transact-SQL statement that scans the same table. Starting with page 200,001, the Database Engine passes the rows from each page it reads back to all three scans. After it reads the 500000 th row, the scan for User-1 is complete, and the scans for User-2 and User-3 wrap back and start to read the pages starting with page 1. When the Database Engine gets to page 100000, the scan for User-2 is completed. The scan for User-3 then keeps going alone until it reads page 200000. At this point, all the scans have been completed
Without this strategy:
"Each user would have to compete for buffer space and cause disk arm contention. The same pages would then be read once for each user, instead of read one time and shared by multiple users, slowing down performance and taxing resources"
Its also called as "Advanced Scanning"
The advanced scan feature allows multiple tasks to share full table scans. If the execution plan of a Transact-SQL statement requires a scan of the data pages in a table and the Database Engine detects that the table is already being scanned for another execution plan, the Database Engine joins the second scan to the first, at the current location of the second scan.
The Database Engine reads each page one time and passes the rows from each page to both execution plans.
This continues until the end of the table's data is reached.
At that point, the first execution plan has the complete results of a scan, but the second execution plan must still retrieve the data pages that were read before it joined the in-progress scan. The scan for the second execution plan then wraps back to the first data page of the table and scans forward to where it joined the first scan. Any number of scans can be combined like this. The Database Engine will keep looping through the data pages until it has completed all the scans. This mechanism is also called "merry-go-round scanning" and demonstrates why the order of the results returned from a SELECT statement cannot be guaranteed without an ORDER BY clause.
i.e:, assume that you have a table with 500000 pages. User-1 executes a Transact-SQL statement that requires a scan of the table. When that scan has processed 100000 pages, User-2 executes another Transact-SQL statement that scans the same table. The Database Engine schedules one set of read requests for pages after 100001, and passes the rows from each page back to both scans. When the scan reaches the 200000 th page, User-3 executes another Transact-SQL statement that scans the same table. Starting with page 200,001, the Database Engine passes the rows from each page it reads back to all three scans. After it reads the 500000 th row, the scan for User-1 is complete, and the scans for User-2 and User-3 wrap back and start to read the pages starting with page 1. When the Database Engine gets to page 100000, the scan for User-2 is completed. The scan for User-3 then keeps going alone until it reads page 200000. At this point, all the scans have been completed
Without this strategy:
"Each user would have to compete for buffer space and cause disk arm contention. The same pages would then be read once for each user, instead of read one time and shared by multiple users, slowing down performance and taxing resources"